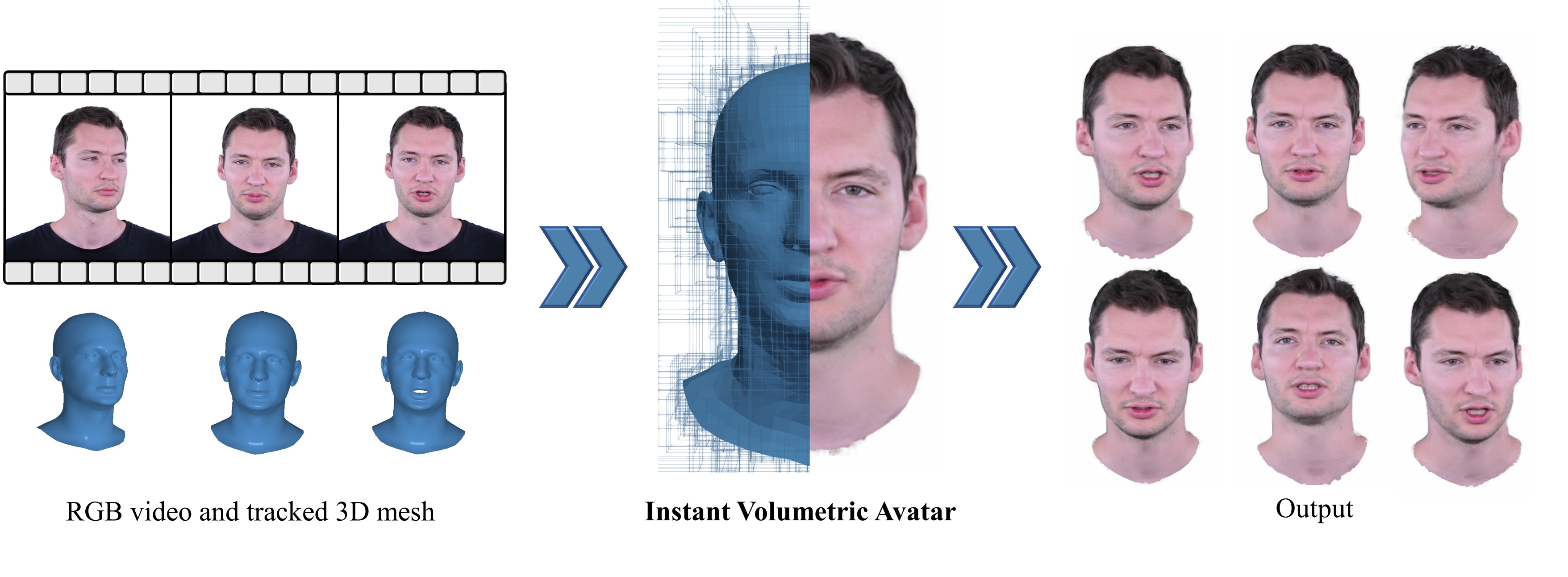
For immersive telepresence in AR or VR, we aim for digital humans (avatars) that mimic the motions and facial expressions of the actual subjects participating in a meeting. Besides the motion, these avatars should reflect the human's shape and appearance. Instead of prerecorded, old avatars, we aim to instantaneously reconstruct the subject's look to capture the actual appearance during a meeting.
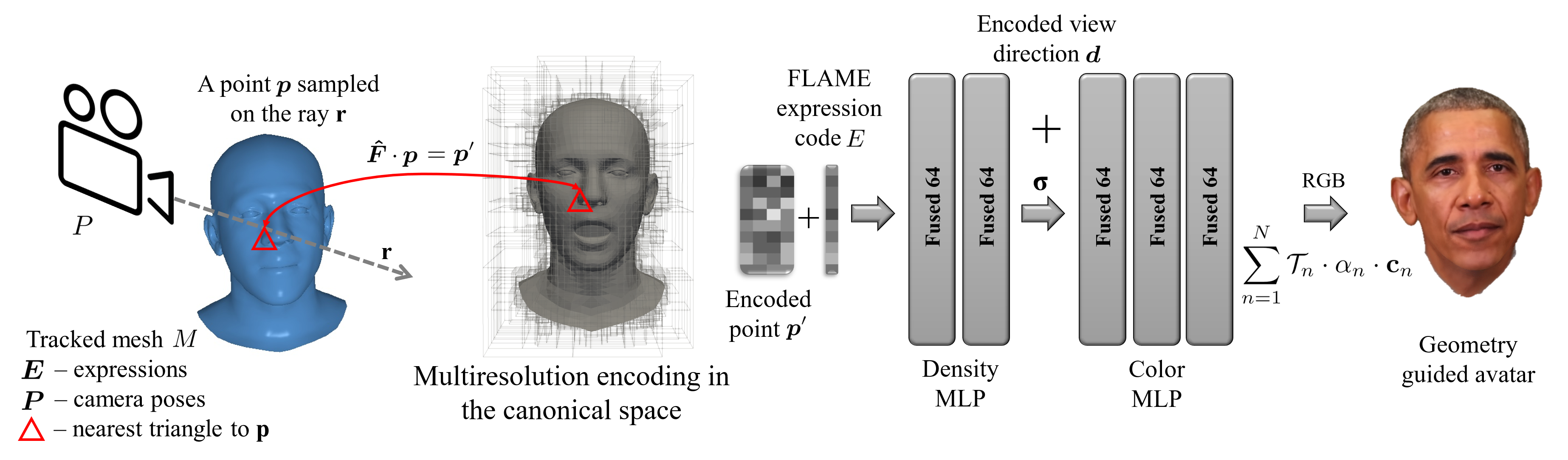
To this end, we propose INSTA, which enables the reconstruction of an avatar within a few minutes (~10 min) and can be driven at interactive frame rates. For easy accessibility, we rely on commodity hardware to train and capture the avatar. Specifically, we use a single RGB camera to record the input video. State-of-the-art methods that use similar input data to reconstruct a human avatar require a relatively long time to train, ranging from around one day Grassal et al. to almost a week Gafni et al. or Zheng et al.
Video
BibTeX
@inproceedings{zielonka2022insta,
title = {Instant Volumetric Head Avatars},
author = {Wojciech Zielonka and Timo Bolkart and Justus Thies},
booktitle = {CVPR},
year = {2023},
pages = {4574-4584},
}