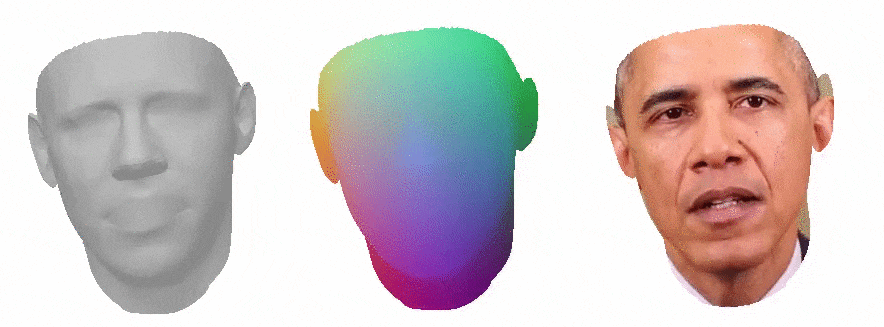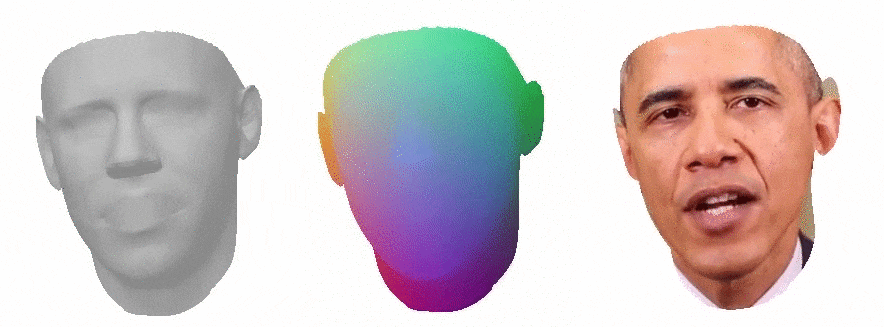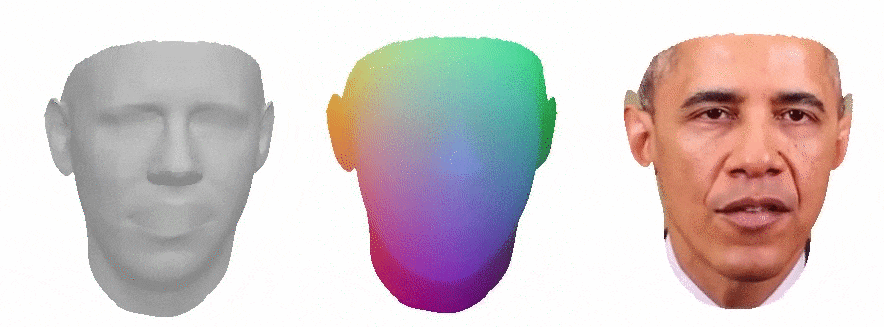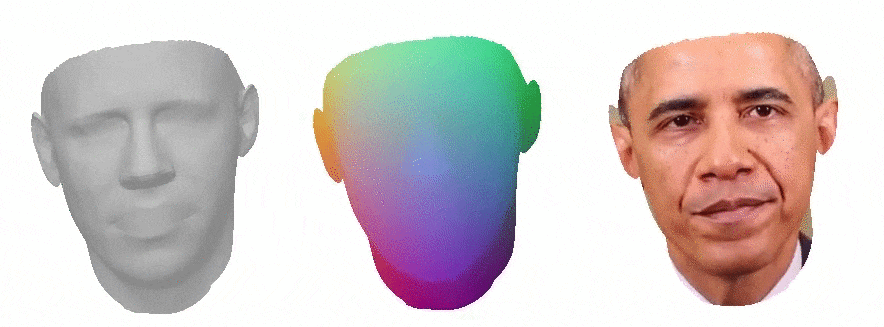
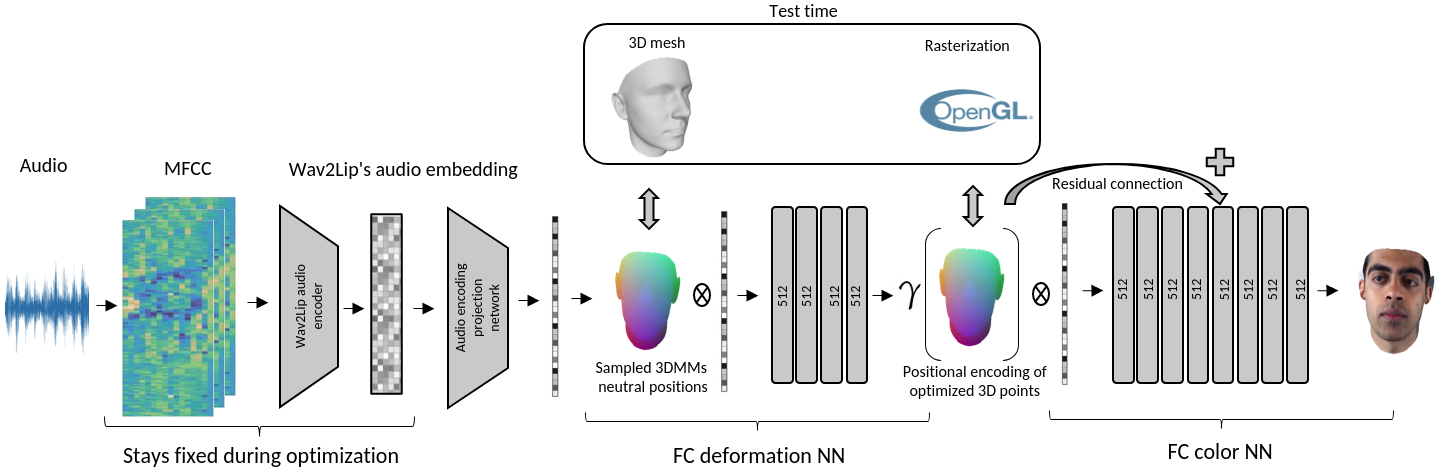
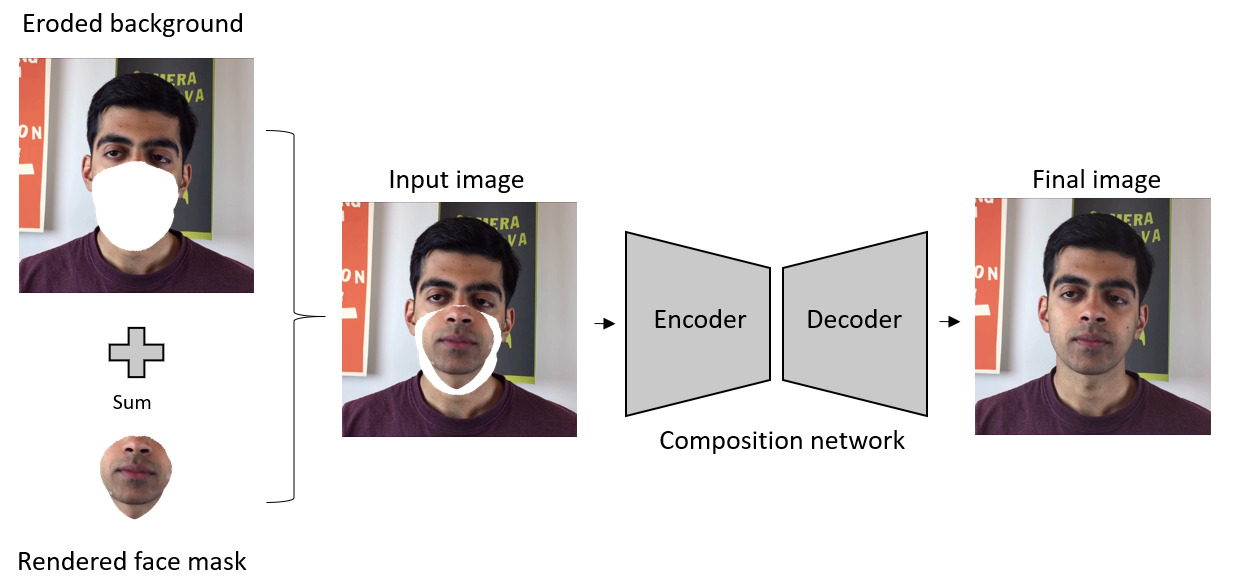
This work is a master thesis which proposes a novel way of synthesizing audio-driven portrait videos. We show that photo-realistic images can be rendered based on a small, fully connected neural network with the positional encoding of 3D face surface and additional audio-features extracted from an arbitrary English speech. The method is based on the intermediate geometry of 3DMMs. However, it is restricted neither by any face model in particular nor by its expression or identity space. The pipeline predicts both RGB color and 3D vertex displacement with respect to the mesh's neutral space for a given speech. Temporal stabilization for audio-feature vectors filtering provides smooth lip-audio synchronization. The rendered face is seamlessly embedded into a background using the autoencoder network with 2D dilated convolutions. Furthermore, the method generalizes well for an arbitrary speech from an unknown source actor on the condition that the English language is used. Finally, some state-of-the-art projects were selected for the method evaluation. Our method outperforms all of them in terms of image quality while maintaining low lip synchronization error.
The source actor is from the series House of Cards.
The source actor is from the movie The Matrix.
Above you can see a comparison to other methods, from the left: our method, Neural Voice Puppetry, Wav2Lip, Wav2Lip GAN.