
We present Drivable 3D Gaussian Avatars (D3GA), a multi-layered 3D controllable model for human bodies that utilizes 3D Gaussian primitives embedded into tetrahedral cages. The advantage of using cages compared to commonly employed linear blend skinning (LBS) is that primitives like 3D Gaussians are naturally re-oriented and their kernels are stretched via the deformation gradients of the encapsulating tetrahedron. Additional offsets are modeled for the tetrahedron vertices, effectively decoupling the low-dimensional driving poses from the extensive set of primitives to be rendered. This separation is achieved through the localized influence of each tetrahedron on 3D Gaussians, resulting in improved optimization. Using the cage-based deformation model, we introduce a compositional pipeline that decomposes an avatar into layers, such as garments, hands, or faces, improving the modeling of phenomena like garment sliding. These parts can be conditioned on different driving signals, such as keypoints for facial expressions or joint-angle vectors for garments and the body. Our experiments on two multi-view datasets with varied body shapes, clothes, and motions show higher-quality results. They surpass PSNR and SSIM metrics of other SOTA methods using the same data while offering greater flexibility and compactness.
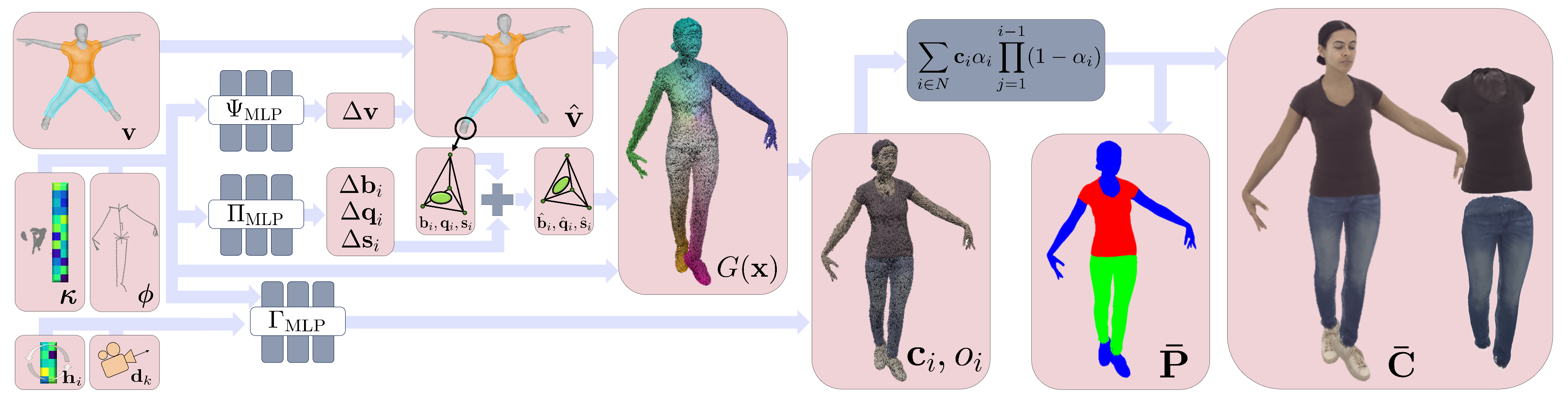
Given a multi-view video, D3GA learns drivable photo-realistic 3D human avatars, represented as a composition of 3D Gaussians embedded in tetrahedral cages. The Gaussians are transformed by those cages, colorized with an MLP, and rasterized as splats. We represent the drivable human as a layered set of 3D Gaussians, allowing us to decompose the avatar into its different cloth layers.
Video
BibTeX
@inproceedings{zielonka25dega,
title = {Drivable 3D Gaussian Avatars},
author = {Wojciech Zielonka and Timur Bagautdinov and Shunsuke Saito and Michael Zollhöfer and Justus Thies and Javier Romero},
booktitle = {I3DV},
month = {March},
year = {2025}
}
*Work done while Wojciech Zielonka was interning at Codec Avatars Lab, Meta, Pittsburgh, PA, USA